Over the course of our project, Dr. Tony Hirst from the Open University has helped us think through the way course data might be visualised and built upon. Recently, he’s written a series of blog posts that discuss this in more detail and offers useful feedback to the project team about our APIs. You can read Tony’s blog posts on OUseful.info
Visualization
Conference Paper Accepted
Back in August, I wrote a blog post that mentioned a paper that I had submitted to The International Conference on Information Visualization Theory and Applications, titled ‘Data Visualisation and Visual Analytics Within the Decision Making Process’. I found out this week that my submission has been accepted as a short paper. It can be downloaded from the Lincoln Repository.
The (short) abstract is included below :
Large amounts of data are collected and stored within universities. This paper discusses the use of data visualisation and visual analytics as methods of making sense of the collected data, analysing it to assess the affects of historical institutional decisions and discusses the use of such techniques to aid decision making processes.
Making Lasagne, Not Spaghetti
The title of this blog post is taken from Noah Iliinsky’s master’s thesis and relates to designing complex diagrams that contain multiple elements, are multi-layered and well ordered, as opposed to ‘spaghetti diagrams’ that “have undefined axes, little or no order, and are a hodgepodge of similar elements”. The thesis highlights key concepts to consider when designing data visualizations and suggests a design process to use, to help create better defined and more meaningful and useful data visualizations. This blog post acts as a quick overview of some of the concepts covered in the thesis, providing a useful list of concepts to consider when designing diagrams / data visualizations. How these concepts directly apply to my work on ON Course will be outlined in a future blog post.
Firstly, how do we define what constitutes a complex diagram? Dictionary definitions don’t really help in this particular context: “The state or quality of being intricate or complicated”. Three criteria are suggested in the thesis, that may contribute towards a diagram being considered as complex.
- At least four different types if information to present
Why four different types? This number was arrived at as the vast majority of visualizations encode three or fewer data types, whereas there are far fewer which encode four or greater types of data. - Large amounts of information
This concept is fairly self explanatory, if you have to present an inordinate amount of data, then whichever method of presentation you choose, it’s going to be a complex diagram. - Presenting qualitative information
Presenting qualitative information leads towards complex diagrams because of a lack of standard metaphors / representations / scales that often exist for quantitative information. As a result of this, the designer / author has to create the representative metaphor themselves, in such a way that the target audience can understand and comprehend the data being shown to them
Why be concerned with how complex a diagram is going to be? More data types to present in the visualization means that more distinct encoding methods are required. “Once the most obvious encoding has been used, the author must venture into more subtle encodings to make their points. Clearly, the more characteristics there are to be represented, the more difficult this becomes.”
Analysing Network Visualization Statistics
As mentioned in a previous post, there are many statistics that can be derived from the network visualizations that I have been generating from the course data I have been collecting. At the moment, these are the particular numbers that I have been paying attention to:
- Mean Degree of Nodes – The mean amount of connections per node on the graph.
- Mean Weighted Degree of Nodes – The mean weight of connections per node on the graph.
- Graph Density – A ratio of the number of edges per node to the number of possible edges.
- Modularity – a measure of the strength of division of a network into modules. Networks with high modularity have dense connections between the nodes within modules but sparse connections between nodes in different modules.
- Mean Clustering Coefficient – the degree to which nodes in the graph tend to cluster together.
So, in terms of applying these to the networks generated with awards data:
- Mean Degree of Nodes – The mean amount of connections for each award. i.e. the mean amount of awards that each award is connected to.
- Mean Weighted Degree of Nodes – The mean weight of connections for each award. i.e. the mean amount of modules shared by that award with other awards.
- Graph Density – The amount of connections per award when compared to the total amount of awards in the network. (more affected by an increase in awards offered than others)
- Modularity – a higher modularity suggests that awards are very highly connected with specific other awards, but have very few ‘odd’ connections to other awards in the network. A very high modularity would suggest that a group of awards shared a lot of modules between themselves.
- Mean Clustering Coefficient – a low coefficient would suggest that awards did not group together, and therefore did not share modules between them. A high coefficient would suggest that most of the awards in the network formed clusters with other awards.
The numbers generated for the weighted connections between awards for the academic year 2006/07 through to 2012/13 are as follows:
| Academic Year | Mean Degree | Mean Weighted Degree | Graph Density | Modularity | Mean Clustering Coefficient |
| 2006 – 2007 | 0.804 | 1.821 | 0.069 | 0.657 | 0.357 |
| 2007 – 2008 | 0.763 | 1.711 | 0.041 | 0.726 | 0.408 |
| 2008 – 2009 | 0.500 | 1.324 | 0.030 | 0.588 | 0.224 |
| 2009 – 2010 | 0.405 | 1.432 | 0.023 | 0.574 | 0.124 |
| 2010 – 2011 | 0.720 | 1.880 | 0.029 | 0.777 | 0.212 |
| 2011 – 2012 | 0.716 | 2.486 | 0.020 | 0.810 | 0.259 |
| 2012 – 2013 | 0.651 | 4.349 | 0.021 | 0.847 | 0.267 |
So what do these numbers show and are they actually useful? Well….
Mean degree shows the amount of awards that each award is connected to, on average. If we look at mean weighted degree instead, we then take into consideration the weight of a connection between a pair of nodes, i.e. the amount of joins between them, rather than just the fact that a join exists. Plotting this graphically helps to show the pattern that emerges.

From the graph above it becomes clear that there is a definite drop on MWD (mean weighted degree) from the academic year 07/08 to the year 08/09 (around 22%), showing that the average amount of links between awards dropped fairly considerably. Through looking back at the university’s history, this can be explained as this was the point in time that the amount of points per module of study was altered, meaning that, essentially, multiple version of the same award were running in tandem: some with the old weighting of awards, some the new. This also explains the steady increase in MWD up to 11-12 which is the first year that the old weighted degrees would not have been active at all. From the highest point of the old weighting, to this point in the new weighting, there is an increase of over 36% in the amount of joins between awards offered at the university. This shows that (assuming an increased modularity is good in terms of curriculum design) that the provision has been improved through the alteration of module weightings. Taking into account the overall increase in the amount of awards offered, this also shows that the restructuring of the modules had a significant impact on the sharing of teaching and assessment across different awards.
The number given for the ‘modularity’ of the graphs shows a couple of interesting things.

As noted above, the modularity shows how well the nodes on the graph (i.e. the awards) form into self contained clusters. A value of 1 would suggest that the awards form perfectly into self-contained clusters, having lots of connections between themselves but no connections with other clusters, a value of 0 would suggest the opposite. As you can see from the graph above, in 06/07, the modularity was reasonably high, quite possibly due to the smaller amount of awards offered at the university. This figure rises over the next year, and then drops for two consecutive years as the weighting of modules at the university goes through a period of change. As the change is fully implemented, the modularity rises significantly and continues to rise, almost at a constant rate from 2010-11 through to 2012-13. This would suggest (though is not necessarily the case) that, either by design or good fortune, the awards offered at the university are starting to form into self-contained groups or areas of specialism. This is interesting to note, as the university has recently gone through an organizational restructuring whereby three colleges were formed – could these clusters be contained within the colleges?
Though this has only looked at two series of numbers generated for each of these visualizations, it does show that visualizing course data produces extra data that cannot be collected when the data is in its raw form. Further to this, it also shows that this data accurately reflects historical changes in provision within the university. If these principles can be applied retrospectively to show changes, in which ways can they be applied to decision making processes, to help assess the impact of potential changes?
Back to Visualizing Course Data!
After having worked on creating a badge system for universities over the past few weeks, I’ve now gone back to looking at how the massive amount of course data that I currently have can be visualized in a meaningful and useful way.
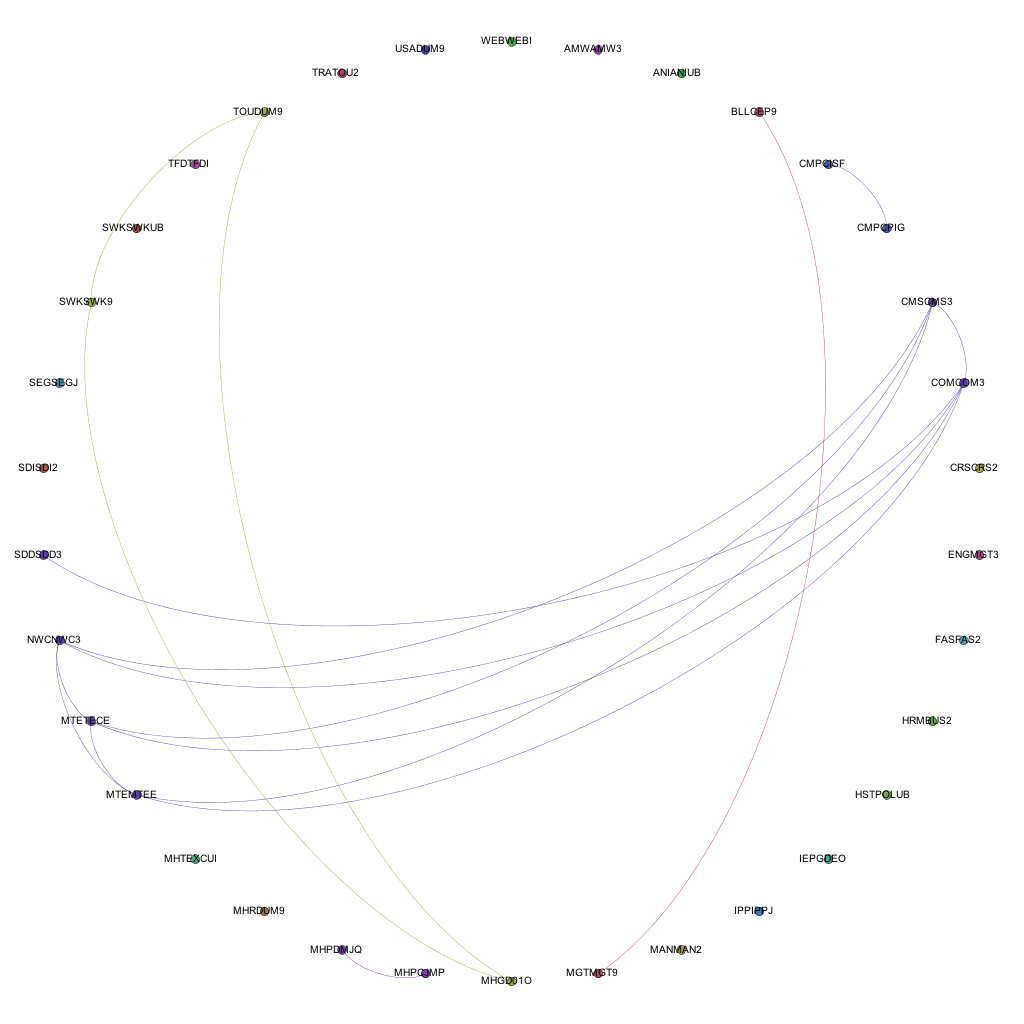
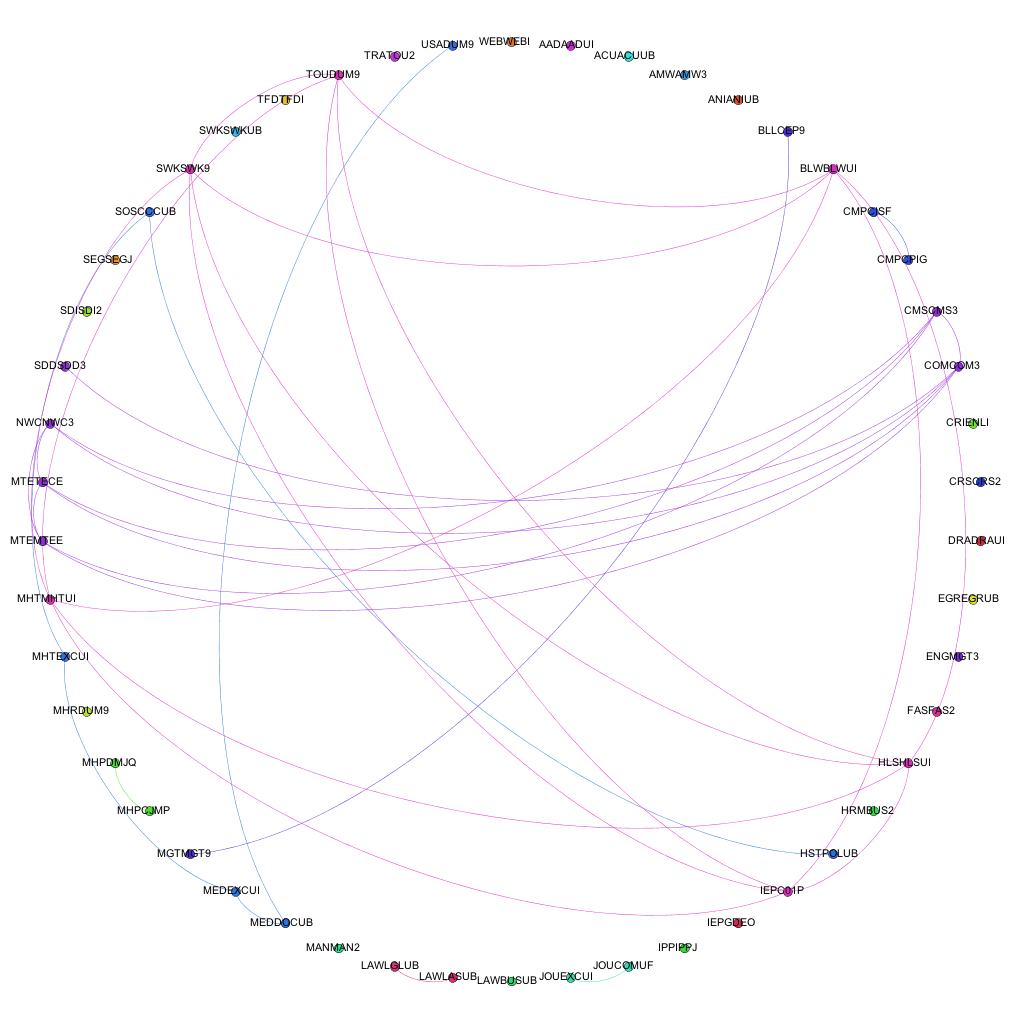
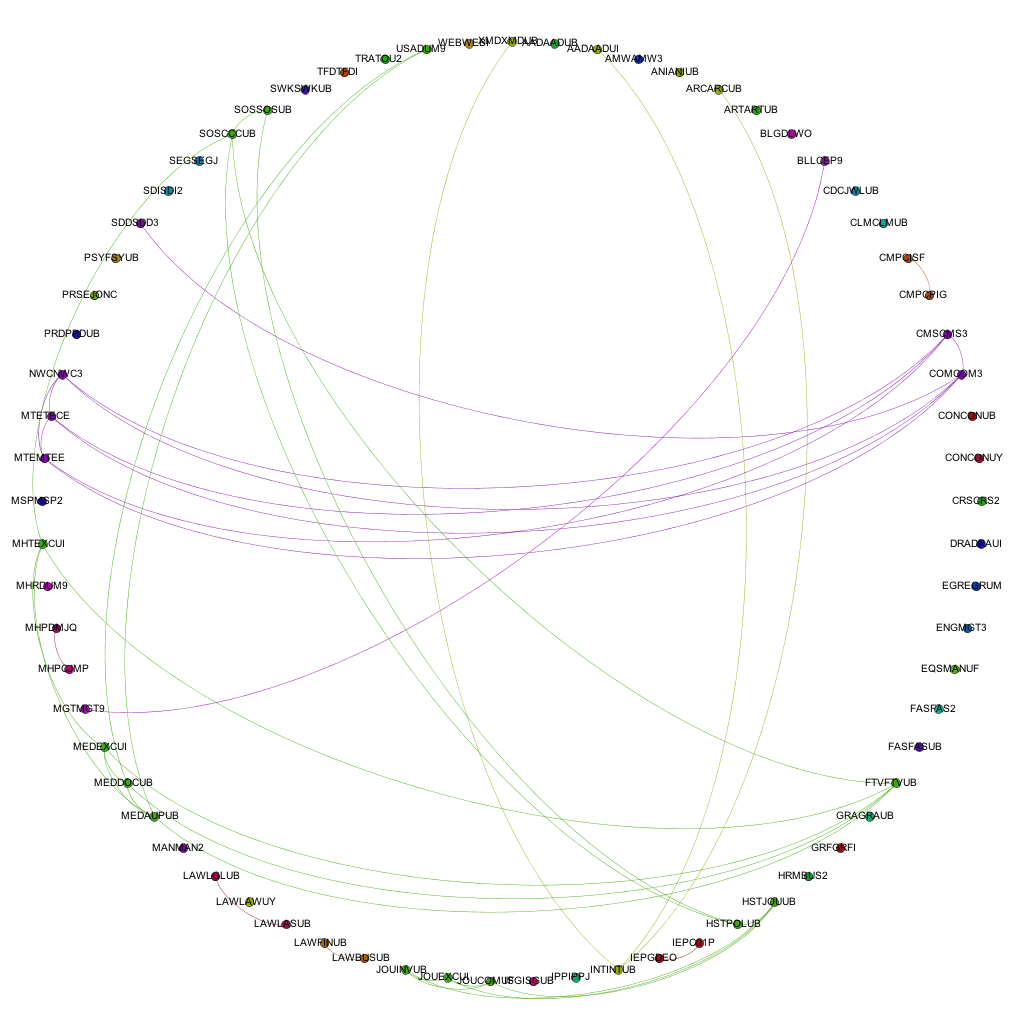
My first bout of visualization resulted in a series of A0 posters showing the links between all of the modules currently being delivered at the university. Whilst these visualizations are very useful for showing the complexity of course structure and relationships, it becomes fairly difficult to extract any information that is particularly useful. For example, the edges in the network denote a connection between two modules in terms of the award that the combination is delivered on. A collection of edges of the same colour show a group of connections for the same award, i.e. a group of modules delivered as part of one particular award.
As the next step in my on-going quest to make sense of all of this course data (and related datasets), I’ve decided to look at a different abstraction of the same datasets, this time looking at the connections on an award level. This is one level of abstraction higher on the scale of University -> College -> Faculty -> School -> Award -> Module. By changing to this level of abstraction, it means that a) there are far fewer nodes on the graph, making it easier to see the information and b) it is easier for people to relate to an award (i.e. more easily recognizable what the node is referring to) than it is at a module level. At the moment, the visualizations are considering data for awards that are ‘Active’ i.e. have students on all levels and have a full-time, ‘traditional’ degree ‘feel’. I chose to do this as taking into account awards that are on their way in or way out, and part-time variations on a theme offered in a full-time course started to distort the data, flooding the networks with nodes and edges that are essentially replicas of other nodes and edges in the graph. Obviously the visualization exercise could be repeated for part-time or post-graduate courses, or to include them.
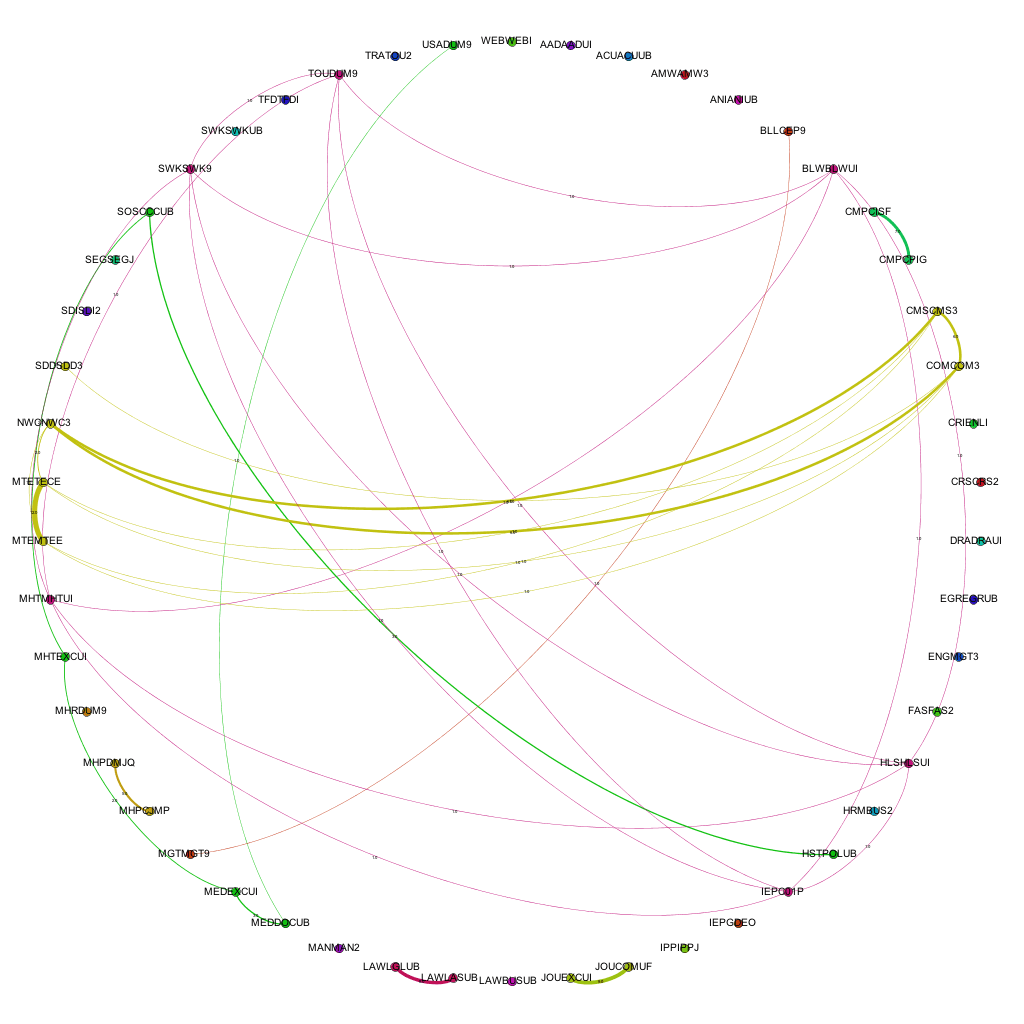
Narrowing the data down as described above, and running it through the trusted Gephi, this time using a circular layout algorithm, produces visualizations such as the following:



Each node around the edge of the graph represents an award that was active at the university for that particular year. With the university being relatively young in the grand scheme of things, the time-span between the first visualization (06-07) and the final (12-13) represent a substantial proportion of the university’s (in its current form) history. Award codes have been used as they are fairly short and remain similar in groups of awards offered by the same departments or schools. By doing so, the relative position of awards is more or less maintained in each visualization. For example. the pattern created between Computer Science awards and Media awards exists and can be easily spotted in each of the visualizations, even though the amount of awards in each visualization changes and the exact award codes of each award code may change. The full collection of visualizations can be accessed here: 2006 – 2007, 2007-2008, 2008-2009, 2009-2010, 2010-2011, 2011-2012, 2012-2013. These visualizations show three different sets of information: the amount of active awards for each year, the codes for the active awards and the relationships (where they exist) between the awards, i.e. where they share modules in common.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
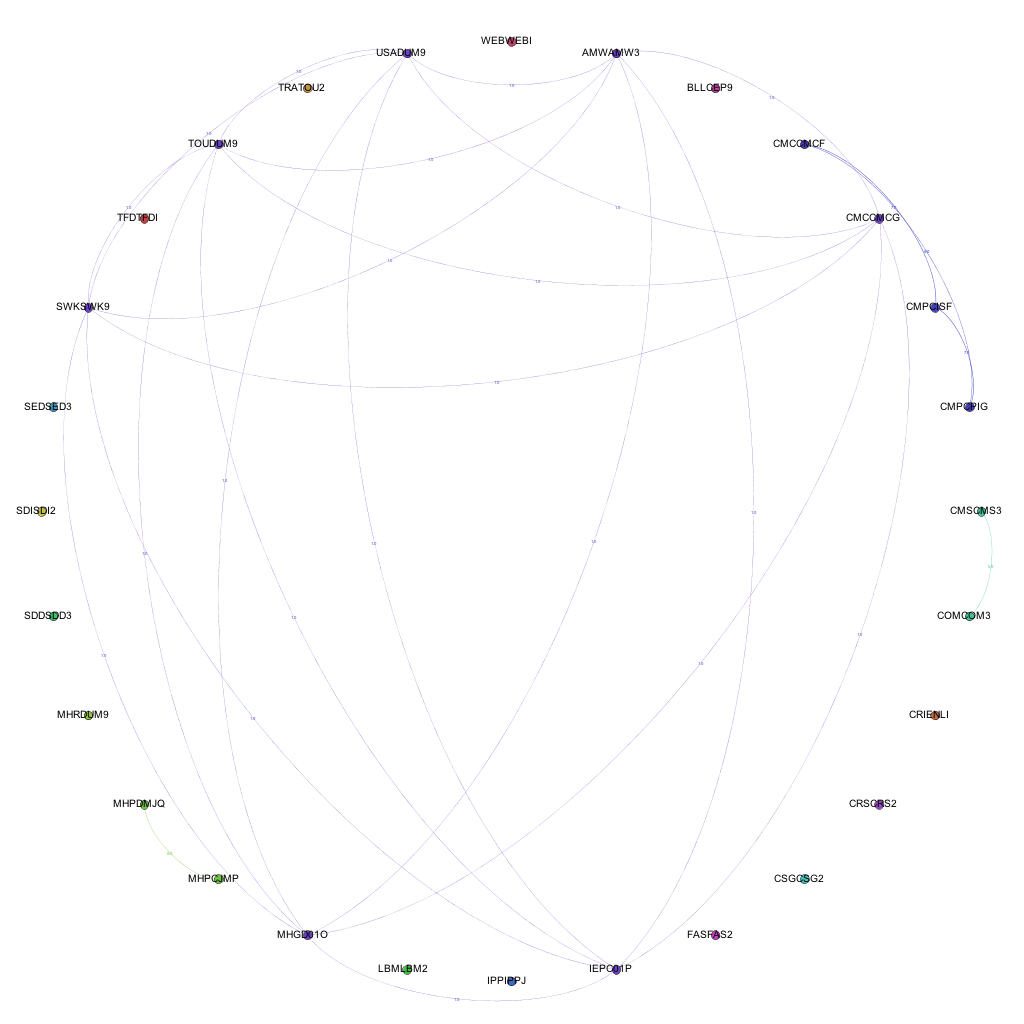
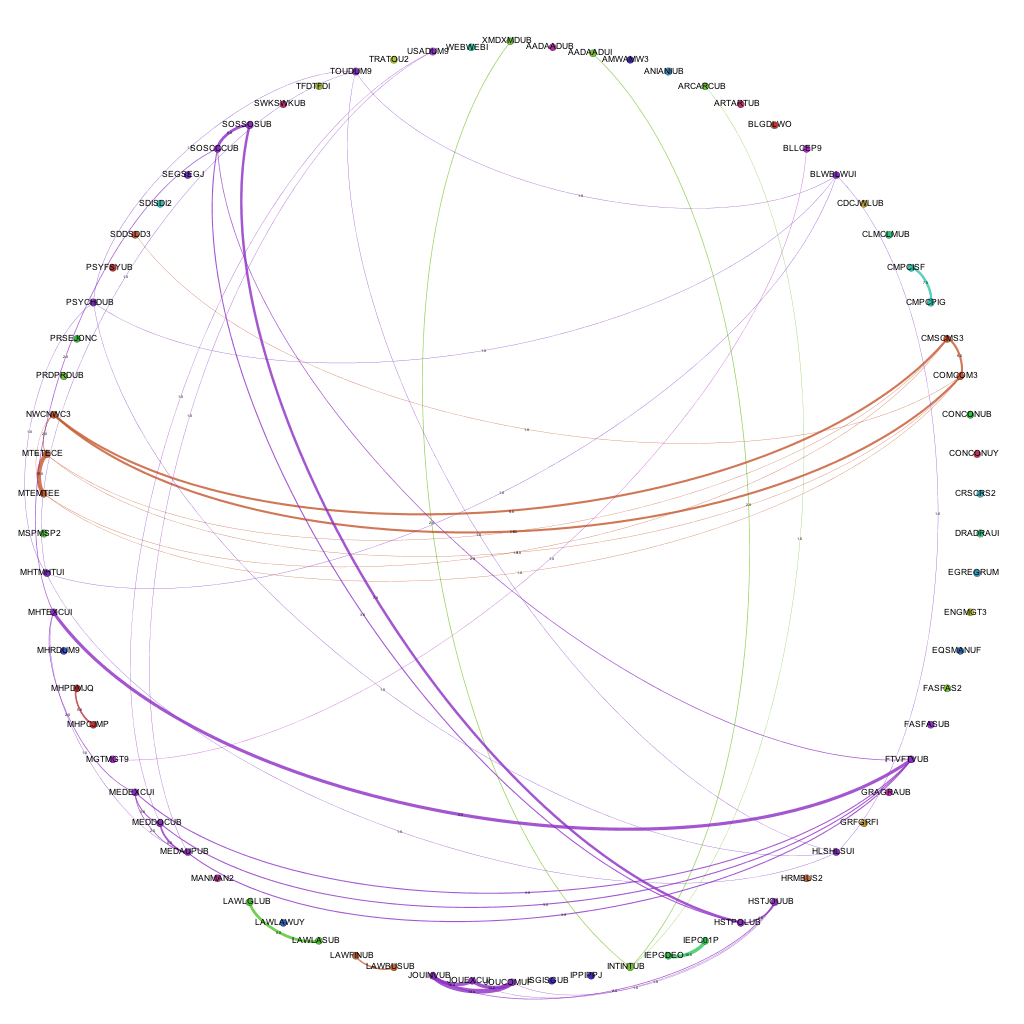
By taking into account the amount of modules shared between the awards and including this in the visualizations, we get a different view of the data. We can not only see where links exist, but also the strength of the links between the awards. Including the amount of modules shared between awards as the weight of each of the edges produces the following visualizations:



The full collection of these visualizations can be found here: 2006-07, 2007-08, 2008-09, 2009-10, 2010-11, 2011-12, 2012-13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
By introducing the weighted edges into the network, we can learn new pieces of information through the visualizations. Whilst the Computer Science – Media pattern exists across several years, we can see it move from being one of the more dominant links (2007-08 / 09-10) to being overshadowed by the amount of modules being shared by, for instance, Film and Television and Media Production and History & Social Science awards.
As well as making pretty pictures with the course data, the statistics associated with these networks can also be analyzed, but that will be the focus for my next blog post.