Back in August, I wrote a blog post that mentioned a paper that I had submitted to The International Conference on Information Visualization Theory and Applications, titled ‘Data Visualisation and Visual Analytics Within the Decision Making Process’. I found out this week that my submission has been accepted as a short paper. It can be downloaded from the Lincoln Repository.
The (short) abstract is included below :
Large amounts of data are collected and stored within universities. This paper discusses the use of data visualisation and visual analytics as methods of making sense of the collected data, analysing it to assess the affects of historical institutional decisions and discusses the use of such techniques to aid decision making processes.
After having worked on creating a badge system for universities over the past few weeks, I’ve now gone back to looking at how the massive amount of course data that I currently have can be visualized in a meaningful and useful way.
My first bout of visualization resulted in a series of A0 posters showing the links between all of the modules currently being delivered at the university. Whilst these visualizations are very useful for showing the complexity of course structure and relationships, it becomes fairly difficult to extract any information that is particularly useful. For example, the edges in the network denote a connection between two modules in terms of the award that the combination is delivered on. A collection of edges of the same colour show a group of connections for the same award, i.e. a group of modules delivered as part of one particular award.
As the next step in my on-going quest to make sense of all of this course data (and related datasets), I’ve decided to look at a different abstraction of the same datasets, this time looking at the connections on an award level. This is one level of abstraction higher on the scale of University -> College -> Faculty -> School -> Award -> Module. By changing to this level of abstraction, it means that a) there are far fewer nodes on the graph, making it easier to see the information and b) it is easier for people to relate to an award (i.e. more easily recognizable what the node is referring to) than it is at a module level. At the moment, the visualizations are considering data for awards that are ‘Active’ i.e. have students on all levels and have a full-time, ‘traditional’ degree ‘feel’. I chose to do this as taking into account awards that are on their way in or way out, and part-time variations on a theme offered in a full-time course started to distort the data, flooding the networks with nodes and edges that are essentially replicas of other nodes and edges in the graph. Obviously the visualization exercise could be repeated for part-time or post-graduate courses, or to include them.
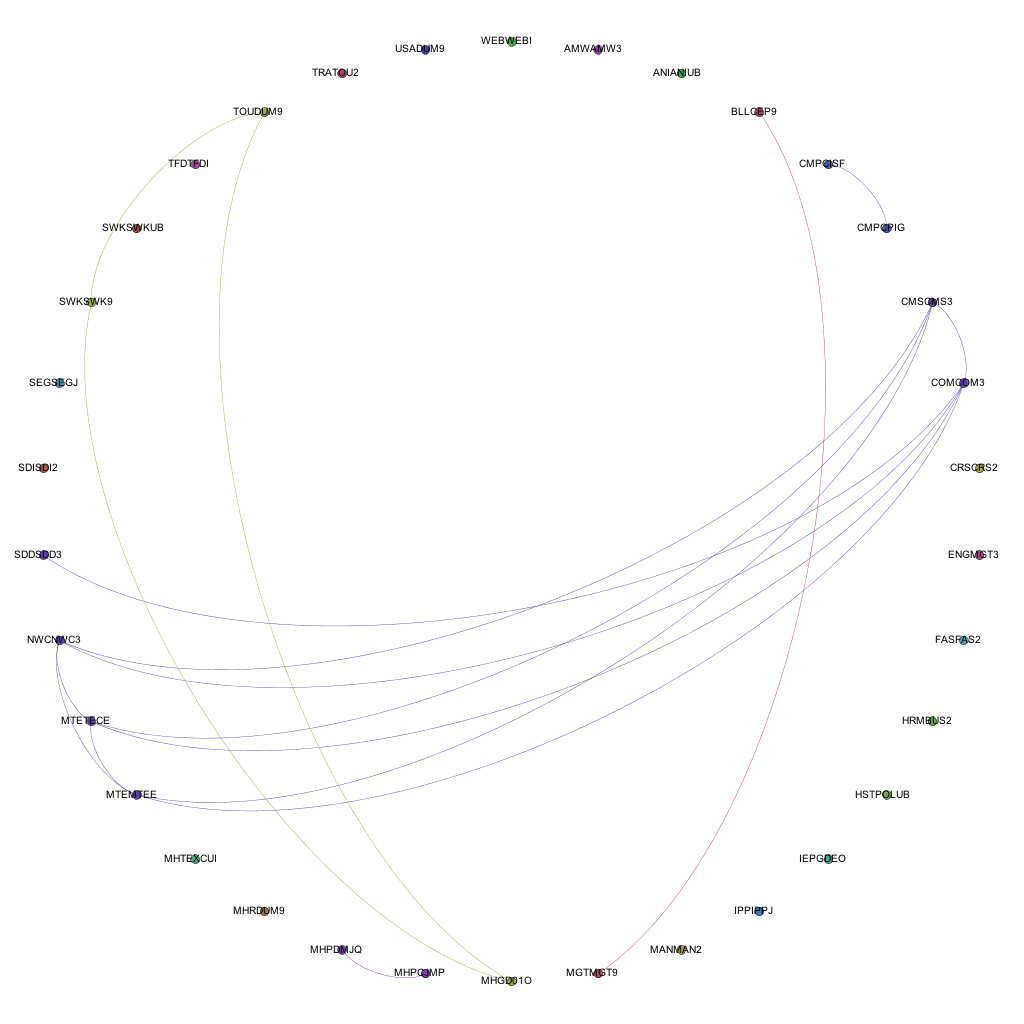
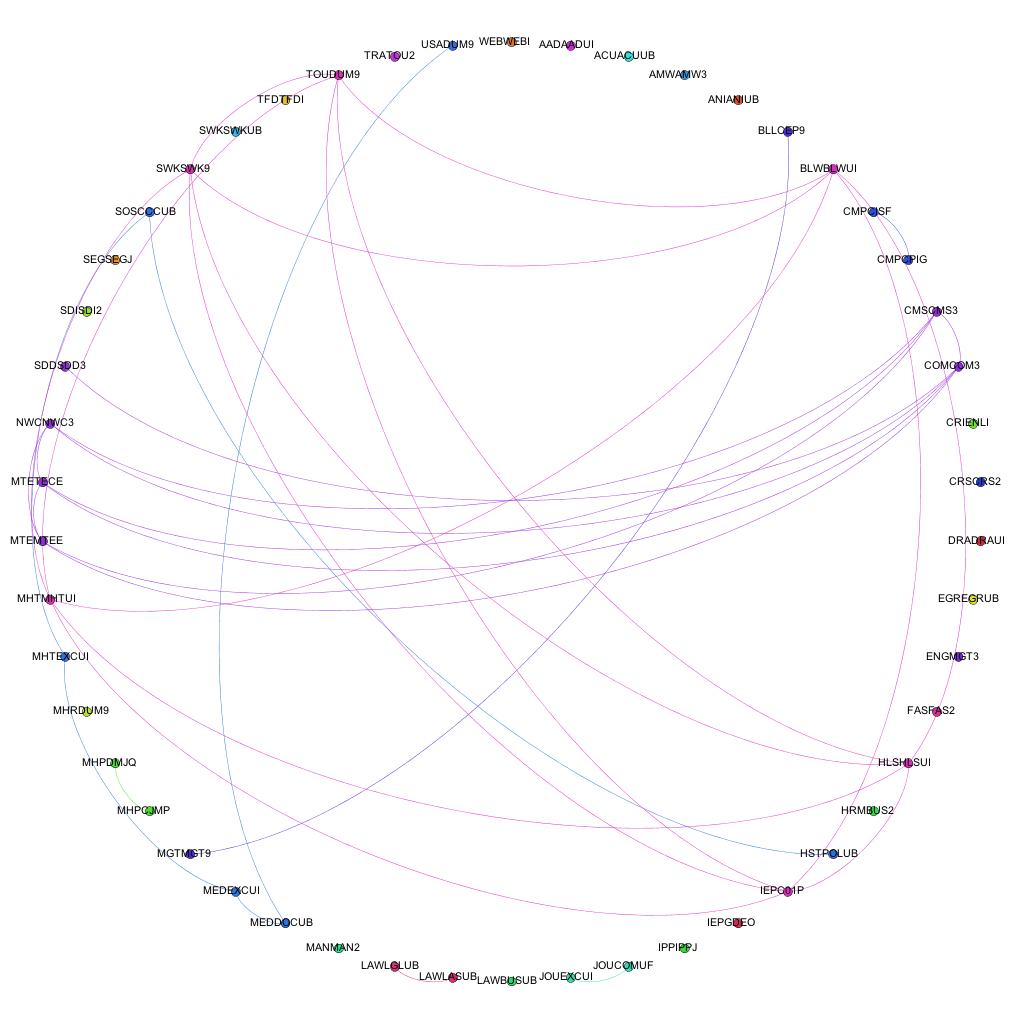
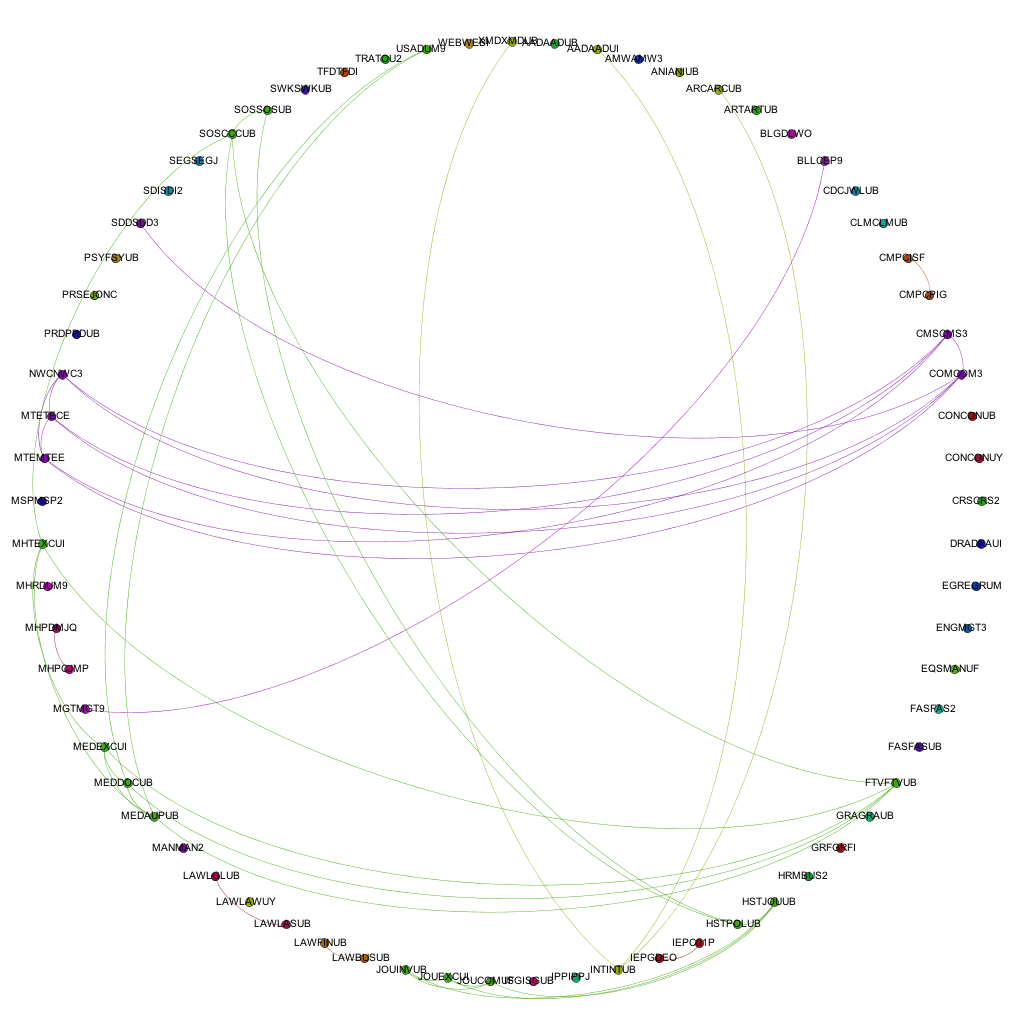
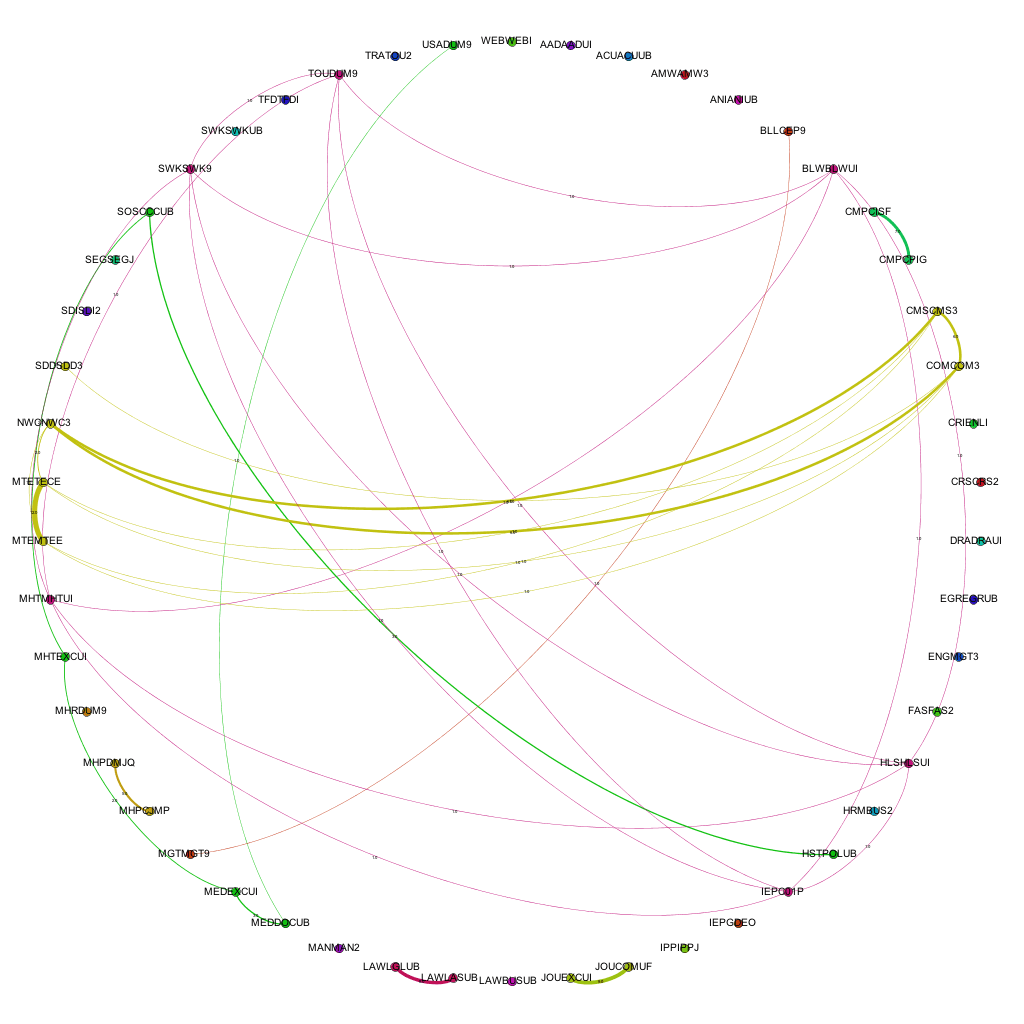
Narrowing the data down as described above, and running it through the trusted Gephi, this time using a circular layout algorithm, produces visualizations such as the following:
Links between awards for 2006-07
Links between awards for 2009 - 10Links between awards for 2012 - 13
Each node around the edge of the graph represents an award that was active at the university for that particular year. With the university being relatively young in the grand scheme of things, the time-span between the first visualization (06-07) and the final (12-13) represent a substantial proportion of the university’s (in its current form) history. Award codes have been used as they are fairly short and remain similar in groups of awards offered by the same departments or schools. By doing so, the relative position of awards is more or less maintained in each visualization. For example. the pattern created between Computer Science awards and Media awards exists and can be easily spotted in each of the visualizations, even though the amount of awards in each visualization changes and the exact award codes of each award code may change. The full collection of visualizations can be accessed here: 2006 – 2007, 2007-2008, 2008-2009, 2009-2010, 2010-2011, 2011-2012, 2012-2013. These visualizations show three different sets of information: the amount of active awards for each year, the codes for the active awards and the relationships (where they exist) between the awards, i.e. where they share modules in common.
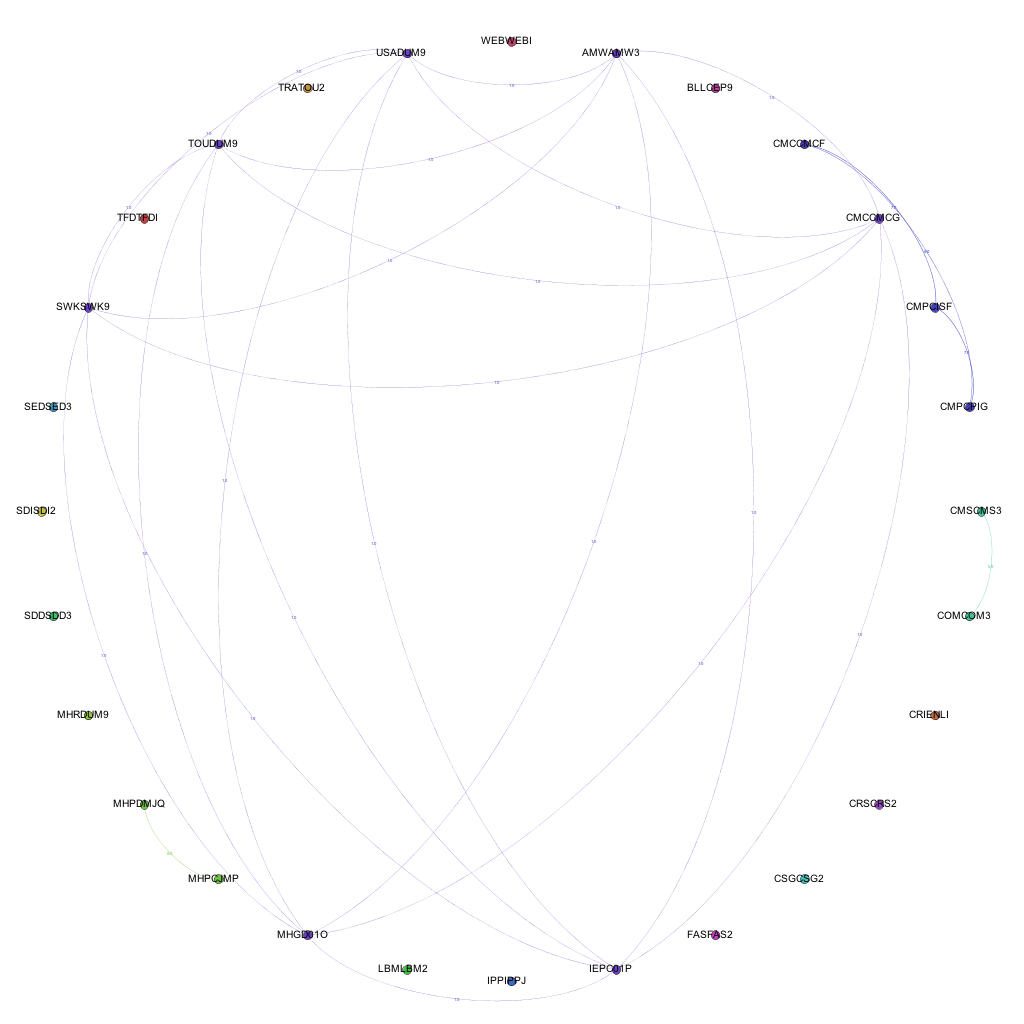
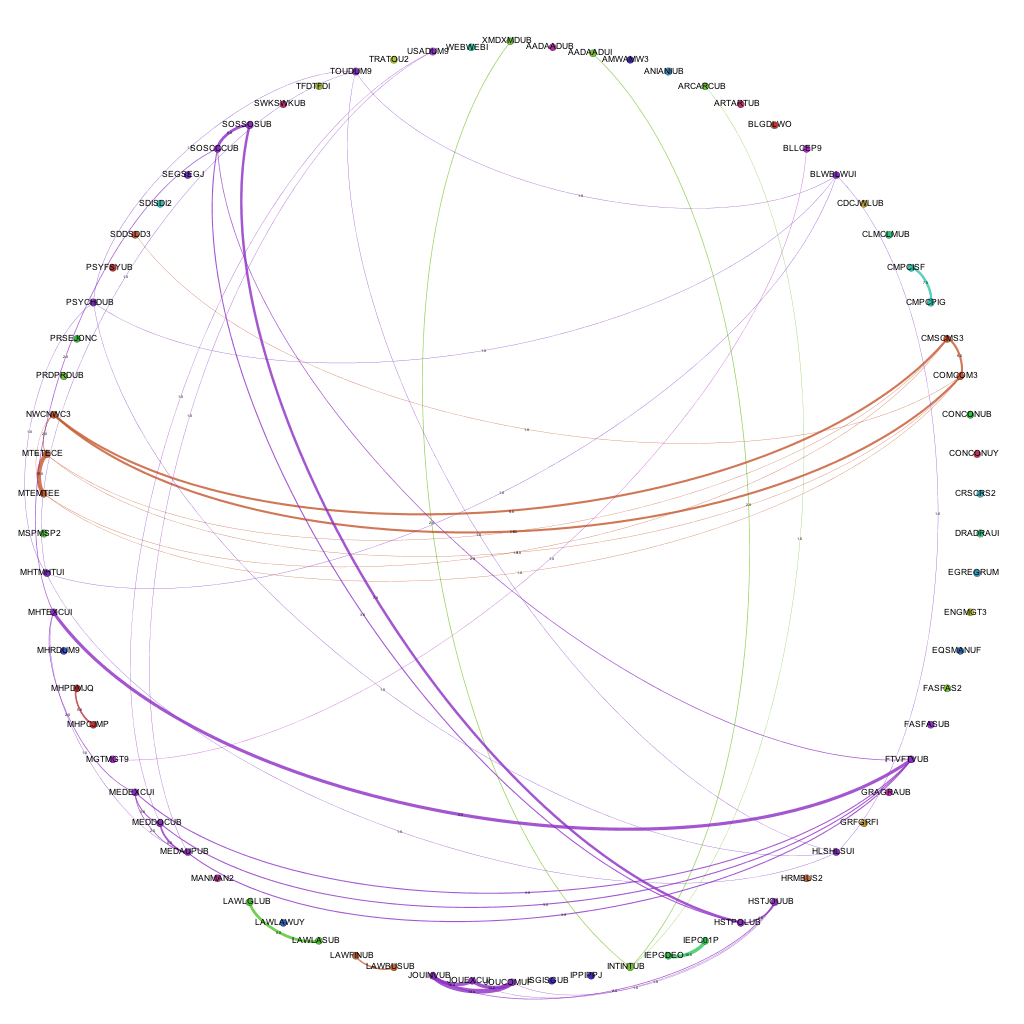
By taking into account the amount of modules shared between the awards and including this in the visualizations, we get a different view of the data. We can not only see where links exist, but also the strength of the links between the awards. Including the amount of modules shared between awards as the weight of each of the edges produces the following visualizations:
Weighted joins between awards 2007-08Weighted joins between awards 2009-10Weighted joins between awards 2012-13
By introducing the weighted edges into the network, we can learn new pieces of information through the visualizations. Whilst the Computer Science – Media pattern exists across several years, we can see it move from being one of the more dominant links (2007-08 / 09-10) to being overshadowed by the amount of modules being shared by, for instance, Film and Television and Media Production and History & Social Science awards.
As well as making pretty pictures with the course data, the statistics associated with these networks can also be analyzed, but that will be the focus for my next blog post.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}