Since we now have access to a very large amount of course data, it is possible to look at ways of improving the presentation of, and access to, this data for (for example) potential students. As such, I’m looking at building a prototype ‘Course Finder’ application.
Building on my work that I outlined in my previous post, we can now identify keywords for all of the courses offered at the university. This offers one way that suitable courses that can be identified for users of the application, likely to be potential students. These courses can also be linked to JACs codes, representing the subjects covered by / in the courses. Courses are also delivered at a particular level – foundation degree, bachelors degree, masters etc.
The criteria that I am currently considering using to identify potential courses for users are: subjects previously studied; subjects interested in and keywords (identified with Open Calais).
As well as using these parameters to produce search results, I have also included features within the application to record ‘click-through’ on search results, as well as the ability to ‘recommend’ a search result as being appropriate and relevant to the search parameters outlined above. As such, the application should ‘learn’ as more and more searches are carried out. If parameters A,B and C are specified and one of the courses recommended as being relevant, then the next time a search is carried out using parameters A,B and C, the same courses should be highlighted as being potentially more useful and relevant to the user.
Database Design
Most of the data required to execute the searches is available from our Academic Programme Management System, through our Nucleus data store. The data relating to the individual search instances, as well as recording click-throughs and recommendations will obviously need to be stored within the application’s database. It may also be necessary to locally store some of the data from Nucleus, in order to improve performance by essentially caching views on the data that are unlikely to change too often, such as links between keywords and courses.
Tables storing data locally include:
- keyword course links
- search instances
- search click-throughs
- search interests
- search keywords
- search studied
- search recommendations
- subjects
- similar courses
The majority of the data stored in the tables listed above relates to Coursefinder-specific functionality, some data has been ‘cached’ from Nucleus, purely to save multiple API calls for data that will change very rarely.
In a follow-up post, I’ll show the created application and describe the benefits and limitations.
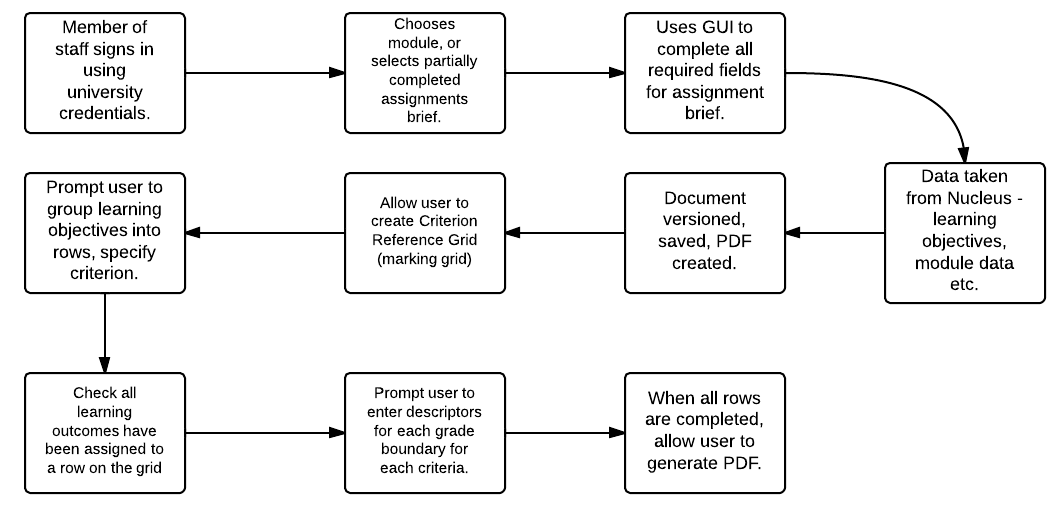 As well as reducing the amount of data that has to be entered by academics (such as learning outcomes, module details etc), the versioning and PDF generation will make the writing process more efficient. Further to this, it allows one lecturer to write a part of the assignment brief, and another to log in and complete the assignment.
As well as reducing the amount of data that has to be entered by academics (such as learning outcomes, module details etc), the versioning and PDF generation will make the writing process more efficient. Further to this, it allows one lecturer to write a part of the assignment brief, and another to log in and complete the assignment.